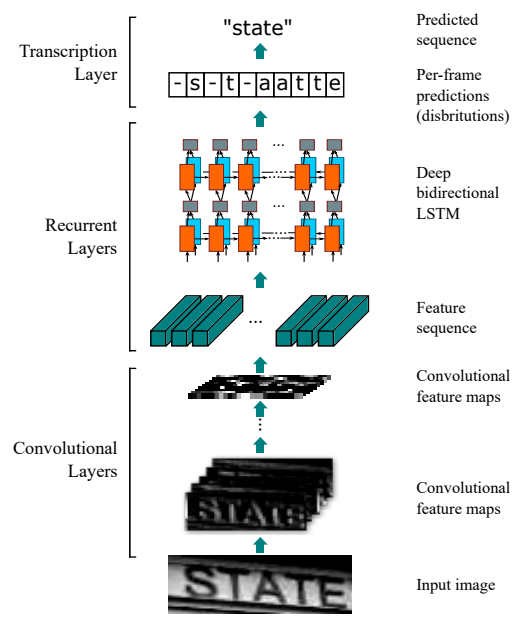
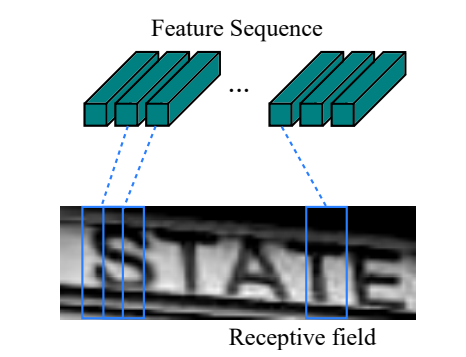
defforward(self, x):# input: height=32, width>=100 x = self.cnn(x) # batch, channel=512, height=1, width>=24 x = x.squeeze(2) # batch, channel=512, width>=24 x = x.permute(2, 0, 1) # width>=24, batch, channel=512 x = self.rnn1(x)[0] # length=width>=24, batch, channel=256*2 x = self.rnn2(x)[0] # length=width>=24, batch, channel=256*2 l, b, h = x.size() x = x.view(l*b, h) # length*batch, hidden_size*2 x = self.fc(x) # length*batch, output_size x = x.view(l, b, -1) # length>=24, batch, output_size return x
# 构建CNN层 def_get_cnn_layers(self): cnn_layers = [] in_channels = self.in_channels for i in range(len(self.cnn_struct)): for out_channels in self.cnn_struct[i]: cnn_layers.append( nn.Conv2d(in_channels, out_channels, *(self.cnn_paras[i]))) if self.batchnorm[i]: cnn_layers.append(nn.BatchNorm2d(out_channels)) cnn_layers.append(nn.ReLU(inplace=True)) in_channels = out_channels if (self.pool_struct[i]): cnn_layers.append(nn.MaxPool2d(self.pool_struct[i])) return nn.Sequential(*cnn_layers)
def_initialize_weights(self): for m in self.modules(): if isinstance(m, nn.Conv2d): n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels m.weight.data.normal_(0, np.sqrt(2. / n)) if m.bias isnotNone: m.bias.data.zero_() elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_()
defencode(self, text): if isinstance(text, str): length = [len(text)] result = [self.encode_map[letter] for letter in text] else: length = [] result = [] for word in text: length.append(len(word)) result.extend([self.encode_map[letter] for letter in word]) return torch.IntTensor(result), torch.IntTensor(length)
defdecode(self, text_code): result = [] for code in text_code: word = [] for i in range(len(code)): if code[i] != 0and (i == 0or code[i] != code[i-1]): word.append(self.decode_map[code[i]]) result.append(''.join(word)) return result
deftrain(root, start_epoch, epoch_num, letters, net=None, lr=0.1, fix_width=True): """ Train CRNN model Args: root (str): Root directory of dataset start_epoch (int): Epoch number to start epoch_num (int): Epoch number to train letters (str): Letters contained in the data net (CRNN, optional): CRNN model (default: None) lr (float, optional): Coefficient that scale delta before it is applied to the parameters (default: 1.0) fix_width (bool, optional): Scale images to fixed size (default: True) Returns: CRNN: Trained CRNN model """
# load data trainloader = load_data(root, training=True, fix_width=fix_width) ifnot net: # create a new model if net is None net = CRNN(1, len(letters) + 1) # loss function criterion = torch.nn.CTCLoss() # Adadelta optimizer = optim.Adadelta(net.parameters(), lr=lr, weight_decay=1e-3) # use gpu or not use_cuda = torch.cuda.is_available() device = torch.device('cuda'if use_cuda else'cpu') if use_cuda: net = net.to(device) criterion = criterion.to(device) else: print("***** Warning: Cuda isn't available! *****")
# get encoder and decoder labeltransformer = LabelTransformer(letters)
print('==== Training.. ====') # .train() has any effect on Dropout and BatchNorm. net.train() for epoch in range(start_epoch, start_epoch + epoch_num): print('---- epoch: %d ----' % (epoch, )) loss_sum = 0 for i, (img, label) in enumerate(trainloader): label, label_length = labeltransformer.encode(label) img = img.to(device) optimizer.zero_grad() # put images in outputs = net(img) output_length = torch.IntTensor( [outputs.size(0)]*outputs.size(1)) # calc loss loss = criterion(outputs, label, output_length, label_length) # update loss.backward() optimizer.step() loss_sum += loss.item() print('loss = %f' % (loss_sum, )) print('Finished Training') return net
deftest(root, net, letters, fix_width=True): """ Test CRNN model Args: root (str): Root directory of dataset letters (str): Letters contained in the data net (CRNN, optional): trained CRNN model fix_width (bool, optional): Scale images to fixed size (default: True) """
# load data trainloader = load_data(root, training=True, fix_width=fix_width) testloader = load_data(root, training=False, fix_width=fix_width) # use gpu or not use_cuda = torch.cuda.is_available() device = torch.device('cuda'if use_cuda else'cpu') if use_cuda: net = net.to(device) else: print("***** Warning: Cuda isn't available! *****") # get encoder and decoder labeltransformer = LabelTransformer(letters)
print('==== Testing.. ====') # .eval() has any effect on Dropout and BatchNorm. net.eval() acc = [] for loader in (testloader, trainloader): correct = 0 total = 0 for i, (img, origin_label) in enumerate(loader): img = img.to(device)
outputs = net(img) # length × batch × num_letters outputs = outputs.max(2)[1].transpose(0, 1) # batch × length outputs = labeltransformer.decode(outputs.data) correct += sum([out == real for out, real in zip(outputs, origin_label)]) total += len(origin_label) # calc accuracy acc.append(correct / total * 100) print('testing accuracy: ', acc[0], '%') print('training accuracy: ', acc[1], '%')
defmain(epoch_num, lr=0.1, training=True, fix_width=True): """ Main Args: training (bool, optional): If True, train the model, otherwise test it (default: True) fix_width (bool, optional): Scale images to fixed size (default: True) """
model_path = ('fix_width_'if fix_width else'') + 'crnn.pth' letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789' root = 'data/IIIT5K/' if training: net = CRNN(1, len(letters) + 1) start_epoch = 0 # if there is pre-trained model, load it if os.path.exists(model_path): print('Pre-trained model detected.\nLoading model...') net.load_state_dict(torch.load(model_path)) if torch.cuda.is_available(): print('GPU detected.') net = train(root, start_epoch, epoch_num, letters, net=net, lr=lr, fix_width=fix_width) # save the trained model for training again torch.save(net.state_dict(), model_path) # test test(root, net, letters, fix_width=fix_width) else: net = CRNN(1, len(letters) + 1) if os.path.exists(model_path): net.load_state_dict(torch.load(model_path)) test(root, net, letters, fix_width=fix_width)
终于,我们可以愉快的训练了:)
1 2 3 4 5 6 7 8 9
if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--epoch_num', type=int, default=20, help='number of epochs to train for (default=20)') parser.add_argument('--lr', type=float, default=0.1, help='learning rate for optim (default=0.1)') parser.add_argument('--test', action='store_true', help='Whether to test directly (default is training)') parser.add_argument('--fix_width', action='store_true', help='Whether to resize images to the fixed width (default is True)') opt = parser.parse_args() print(opt) main(opt.epoch_num, lr=opt.lr, training=(not opt.test), fix_width=opt.fix_width)