这篇文章是对目标检测算法的一个小总结,归纳一下主要的几个物体检测算法。
目标检测,最暴力的方法就是:
- 首先通过不同大小,不同长宽比的窗口在图片上滑动。
- 再将每个窗口的图像输入到分类器中,得到概率。
- 最后根据概率判断此框内是否有物体,有什么物体。
但是这时间复杂度显然是难以接受的,因此就有了后面的种种算法,让目标检测也能更加优雅。
RCNN
RCNN是第一个将深度学习引入物体检测并取得突出成绩的算法,它用CNN替代传统机器学习算法。论文PDF在这里
RCNN主要步骤如下:
- 通过 selective search 算法,在整张图片上获得2000个 region proposal(候选框)。
- 将候选框输入到CNN,得到特征图。
- 将特征送入SVM分类器,判断物体类别。
- 使用回归器调整候选框位置。
细节:
- 第一步提取候选框可以有很多种方法,论文中用的是 selective search,更多的方法大家可以看论文。
- 输入CNN之前,每个候选框都要缩放到固定大小,因为网络最后的全连接层要求输入大小固定。
- CNN初始为在ImageNet上预训练的模型,只将最后一层用随机初始化替换,之后才在要检测的训练集上进行微调,可以提升效果。(下面介绍的算法也都采用了此策略)
- 物体类别要加一个背景类,来表示没有物体的候选框。(之后的算法同)
- 将与真实框重叠度大于阈值(IoU>0.5)的候选框作为正样本。
- 由于正负样本不平衡,要在每个batch中调整正负样本比例进行训练。(之后的算法同)
- 经过SVM后要进行NMS(非极大值抑制)(之后的算法同,最后都要NMS)
成果:
- 使用Alexnet,在PASCAL VOC2007上的检测结果从DPM HSC的34.3%提升到了54.2%(mAP)。
- 使用VGG-16,可以将mAP提升到66%,但速度变慢很多。
RCNN成功的原因:
- 用2000个候选框代替滑动窗口,速度提高。
- 通过CNN提取特征,效果较好。
- 用大型辅助训练集对CNN进行预训练,缓解了物体检测训练数据较少的问题。
RCNN的缺点:
- 速度不够快,处理1张图片需要47s。
- 训练中,由于图片特征量巨大,必须通过硬盘暂时存储,占用磁盘空间大且速度慢。
- 模型复杂,分为三步,难以训练。
SPP-Net
SPP-Net在RCNN的基础上,大大提升了检测速度。论文PDF
首先如前面所述,CNN要求输入的图片大小固定。图片输入卷积层后,经过多次卷积池化,得到一定大小的特征图;之后需要将特征图展开到一维并输入全连接层。卷积层本身并不要求输入图片的大小固定,但展开后得到的一维向量的长度必须固定,否则无法输入全连接层。这就意味着输入的图片大小也必须固定,于是2000个候选框必须缩放到固定大小才能输入,这就造成了RCNN的低效。
SPP-Net为了解决这个问题,采用了金字塔池化。将最后一个卷积层输出的特征图,分别用 4 x 4, 2 x 2, 1 x 1 的网格分为16、4、1个块,在每个块中取最大值或平均值,从而得到16+4+1个特征值组成的特征向量。用它来输入全连接层,这样,输入图片大小就不必固定了。我们就可以不单独对每个候选框进行计算,而是将整个图片输入,然后依据原图与特征图的对应关系,取出每个候选框对应的特征,通过金字塔池化与全连接层后再输入给SVM进行分类。
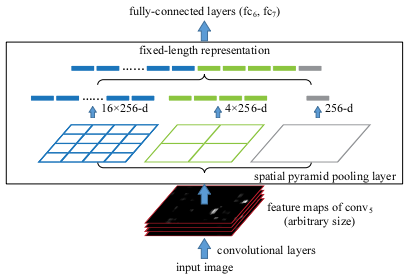
SPP-Net的优势是十分明显的,对每张图片,RCNN的CNN网络需要进行2000次运算,而SPP-Net只需要1次。准确率上两者较为接近,SPP-Net略有提高。
Fast-RCNN
Fast-RCNN在SPP-Net的基础上,将提取特征、分类器分类、位置调整这3步统一用神经网络来完成。论文PDF
Fast-RCNN主要步骤:
- 通过 selective search 算法,在整张图片上获得2000个 region proposal(候选框)。
- 将图片通过网络,得到物体分类结果以及边框位置调整的回归结果。
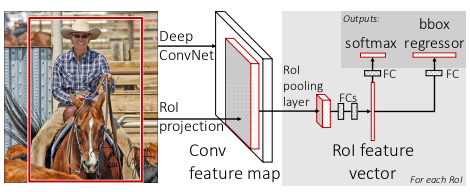
Fast-RCNN的改进:
- 采用与SPP-Net类似但更简洁的 RoI pooling 层,用一个 7 x 7 的网格代替SPP-Net的三个网格,同样起到了提升速度的作用。
- 用神经网络完成提取特征、分类器分类、位置调整这3步,简化了算法,同时,这3步得以在GPU上计算,提高了效率。
- 使用多任务损失作为损失函数训练网络,损失函数定义如下:
$$ L (p,u,t^u,v) = L_{cls}(p,u) + \lambda[u \ge 1]L_{loc}(t^u,v) $$
其中u为真正类别,u为0时为背景类;$t^u = \{t^u_x,t^u_y,t^u_w,t^u_h\}$,是预测的K个类别中第u类的位置信息;$v = \{v_x,v_y,v_w,v_h\}$,是物体的真正位置信息;$[u \ge 1]$,表示当u=0为背景类时,无定位损失。
分类损失为负对数损失:
$$L_{cls} = -log p_u$$
位置损失与L1损失相似:
$$L_{loc} = \sum_{i \in \{x,y,w.h\}} smooth_{L_1}(t^u_i - v_i)$$
$$
smooth_{L_1}(x) =
\begin{cases}
0.5 x^2,& \text{if $|x| \lt 1$ }\\
|x| - 0.5,& \text{otherwise}
\end{cases}
$$
成果:
- 在PASCAL VOC2007上的检测结果提高到了70%(mAP)。
- 速度进一步提高到了3s每张。
不足:
- Fast-RCNN简化了算法,但并没有实现端到端。
- 处理一张图片,用的3s中,第二步只占了0.23s,大部分时间耗费在第一步提取候选框上,无法实时检测。
Faster-RCNN
Faster-RCNN在Fast-RCNN的基础上,将速度较慢的候选框提取,通过神经网络完成,用GPU计算,速度更快。论文PDF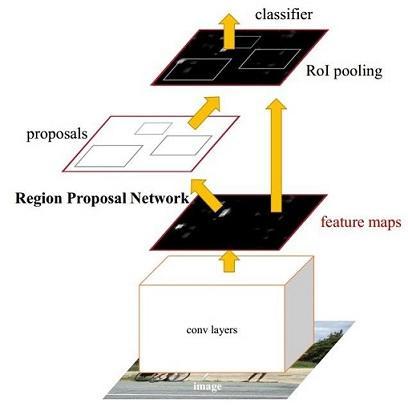
Faster-RCNN主要步骤:
- 首先输入整张图片得到特征图。
- 再将特征图输入RPN网络,得到候选框。
- 最后根据候选框,对特征图相应位置处理,得到类别信息,以及位置调整信息。
这三步都通过神经网络完成,其中更详细的步骤如下图(引自此处)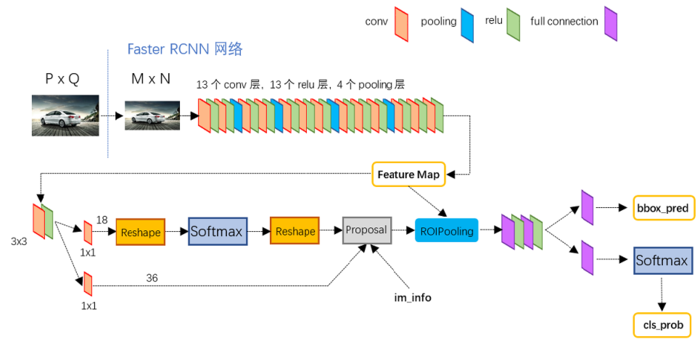
得到 feature map(特征图)后,它会被输入到RPN网络,之后又会在 RoI pooling 层用到。RPN网络中又有两个分支,上面的分支用来判断是否有物体,下面的分支用来调整位置。RPN首先会在特征图的每个像素点提取3种大小,3种比例的候选框(anchor),共3×3=9个,对每个候选框得出物体判断得分以及位置调整信息,最后在proposal层整合得到最后的候选框,传入 RoI pooling 层。后面的就与Fast-RCNN相同了。
这里候选框的3种长宽比分别为 1、2、0.5,作者将这样的候选框称作anchor,后面的SSD也吸收了此思想。
训练:
论文中,训练分四步进行:
- 在ImageNet训练集上训练RPN后再微调。
- 用1中训练好的RPN获得候选框,微调在ImageNet上预训练的Fast-RCNN。
- 固定两者共有的卷积层,重新初始化RPN,使用2中训练的Fast-RCNN微调RPN中独有的层。
- 固定两者共有的卷积层,微调Fast-RCNN独有的层。
成果:
- 实现了端到端,简化了训练与测试。
- 速度更快,更加准确,速度达到每秒5张,mAP为73.2%。当然也可以换用简单的网络,牺牲准确率换取速度。使用ZF网络时,可以达到17张每s,mAP也下降至60%以下。
不足:
仍然做不到实时检测。
YOLO
之前的三个算法,都是先找到候选框,再根据得分判断类别。而YOLO则采用了另一种暴力直接的方式,用回归,一次将位置与类别概率都输出出来。论文PDF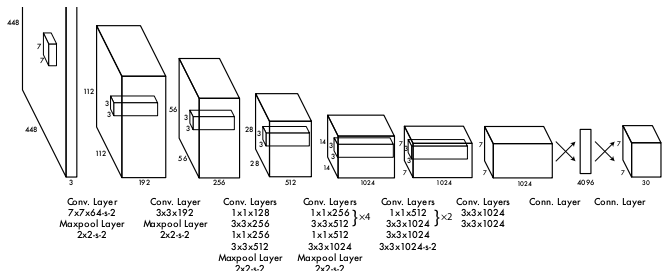
步骤:
YOLO将每个图片用7 × 7的网格分为49份,每一个网格预测两个 bbox(bounding box) 和一个物体类别,物体类别由20个类的置信度判断;每个 bbox 又要预测出其置信度和位置信息(x,y,w,h)一共 1+4 个值。所以每个网格就有 20+2×(1+4)=30 个输出,最终的输出即为 7 × 7 × 30 的张量。
训练细节:
- 训练时,真实物体中心落在哪个网格,哪个网格的bbox置信度就为此bbox与真实框的IoU值,其余网格置信度为0。(可以称之为“此网格对这个真实框负责”,或“此网格与这个真实框匹配”)
- 对于同样的预测偏离距离,大小较小的物体更难以忍受此误差,因此,作者将框的宽与高取平方根后再计算平方误差。这样,对于同样的偏离距离,小框的损失将更大。
- 对于位置误差和分类误差,作者都用的是平方误差,同时,通过系数调节各误差间的关系。
成果:
- 速度上取得大突破,达到每秒45张的速度,可以实时检测,mAP为 57.9%。
- 暴力直接而不失优雅,告诉了我们“网络用的好,什么对应关系都能学出来”的道理。
缺点:
- 准确度不高,对不同大小的同种物体的泛化能力较弱。
- 对于较小的物体和成群的物体效果不好,因为每个框内只有两个bbox,且两个bbox为同一类别。
SSD
之前介绍的Faster-RCNN与YOLO都不完美,mAP与速度没能兼得。SSD便糅合了两者,结合了YOLO的思路以及Faster-RCNN的anchor的思想。论文PDF
网络结构
大致网络结构如下: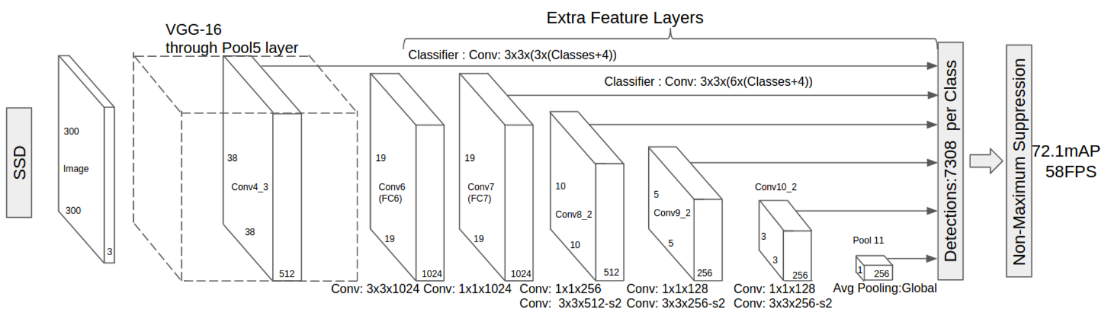
- 最左边为输入的 300 × 300 的图片。
- 之后的正方体为VGG-16的卷积层与池化层。
- conv6与conv7分别由原来VGG-16的FC6与FC7转化而来。
- 然后是三组卷积层,结构在图下方有标注。
- 最后是一个平均池化层。
步骤:
- SSD首先将 300 × 300 的图片输入网络得到图中的6组特征图。
- 在每个特征图的每个像素点产生一定数量的anchor(默认框)。
- 然后每组特征分别通过 3 × 3 的卷积核最终得到预测框相对与默认框的偏移以及分类概率。
anchor的选择:
对于anchor的大小,论文中给出的公式为
$$s_k = s_{min} + \frac{s_{max} - s_{min}}{m-1}(k-1), \ \ \ \ \ \ k \in [1, m]$$
其中$m$为特征图的个数6,$s_{min}$与$s_{max}$分别定为0.2与0.95,求得的$s_k$即为anchor的尺寸。再取不同长宽比的anchor,长宽比用$a_r$表示,$a_r = \{ 1, 2, 3, \frac{1}{2}, \frac{1}{3} \}$,则每个anchor的宽与高就可以得到:
$$w^a_k=s_k \sqrt{a_r} \\ h^a_k=s_k/\sqrt{a_r}$$
不过在第一个特征图上,因为这个特征图较大,作者只用了长宽比为$1, 2, \frac{1}{2}$的这三种anchor,而在其余五个特征图上,除了上述五种长宽比的anchor外,作者还增加了一种新的长宽比为1但尺寸为$s^{\prime}_{k}=\sqrt{s_k s_{k+1}}$的anchor。因此,总共的anchor数为$38^2 \times 3 + (19^2 + 10^2 + 5^2 + 3^2 + 1^2) \times 6 = 7308$。
细节:
- 通过在六组不同大小的特征图上的卷积,网络得以适应不同大小的物体,特征图越小,感受野越大。
- 训练时,若anchor与真实框的IoU值大于阈值(0.5),此anchor就负责预测此真实框,这一点与MultiBox类似,但不同的是,这里允许多个anchor负责同一个真实框。
- 最终损失为位置损失与分类损失的加权和,其中位置损失采用Fast-RCNN中的$smooth_{L_1}(x)$,分类损失为softmax损失。
成果:
继承了YOLO与Faster-RCNN各自的优点,在速度与效果上做到了两全。
总结
最后给这里讲的各个算法的成果列个表:
| Name | mAP | speed | feature |
|---|---|---|---|
| RCNN | 66% | 1/47 fps | selective search 提取候选框;CNN提取特征 |
| Fast-RCNN | 70% | 1/3 fps | 加入类似SPP-Net的 RoI pooling;神经网络完成分类与位置回归 |
| Faster-RCNN | 73.2% | 5 fps | 用RPN提取候选框 |
| YOLO | 57.9% | 45 fps | 化为回归问题暴力直接 |
| SSD | 74.3% | 58 fps | YOLO + anchor + 多尺度特征图 |