人体姿态估计(human pose estimation)即人体关键点检测
传统方法
传统方法都是基于模板匹配的思想
比如Pictorial Structure,这是一个比较经典的传统思路,主要考虑单元模板以及模板关系。此算法在模板关系中使用弹簧模型,保证模板间的相对关系和灵活性。
深度学习的 Ground Truth
对于人体骨骼关键点检测的 Ground truth,主要有三种: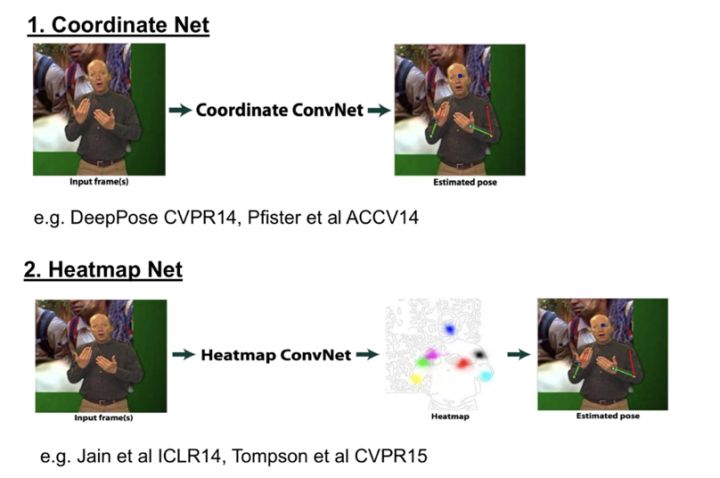
- Coordinate(坐标点),直接将关键点的坐标作为网络的回归目标。(2015 年之前
- Heatmap(热力图),即对每种关键点构建一个热力图,热力图中每个点的大小表示此点为某类点的概率,距离关键点越近概率越大。训练模型回归每个像素的概率即可。
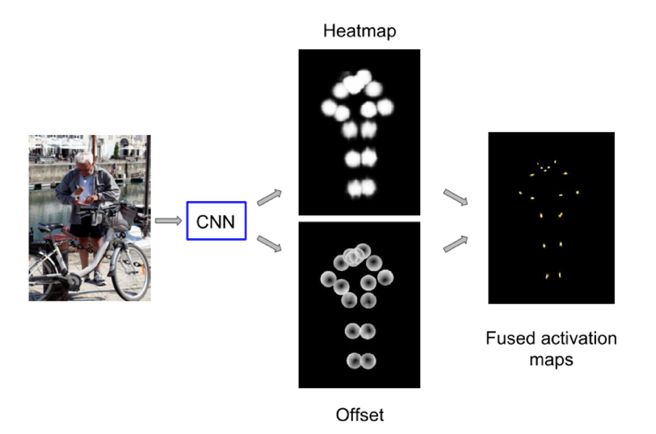
- Heatmap+Offset,是前两种的结合,在关键点周围的一定范围内,所有点概率均为1,且用一个offset来表示这些点与关键点的关系。(只在Google的G-RMI中用到
在heatmap中,当两个点距离较近时,采用Average或Max作为最终的置信度。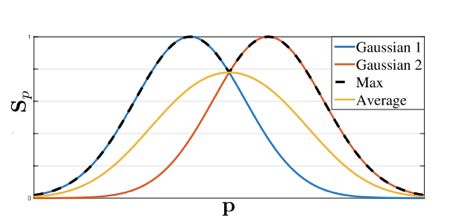
从效果上看 heatmap 比 coordinate 好不少。
深度学习方法
人体姿态估计,按分类问题,分为单人姿态估计和多人姿态估计。
多人姿态估计主要又分为两个方向,一个是Top-Down(从上到下),一个是Bottom-Up(从下到上)
- Top-Down 首先提取 human proposal ,抠出每个人,一般使用常用检测方法如Faster-RCNN、SSD等,再对crop出的图片进行关键点检测
- Bottom-Up 先检测出所有的关节,再将关节聚类成每个人
Single Person
DeepPose(first one), CPM(multi-stage),
Stacked Hourglass Networks
此模型主要是网络结构比较新颖
首先介绍Hourglass Network,它采用U型网络结构,类似于FCN,结构如下: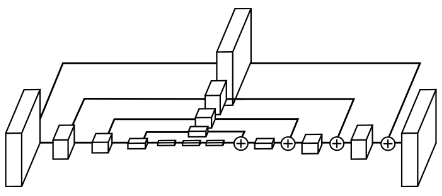
图中每一个块都是一个bottle-neck块,下采样采用max-pool,上采样采用nearest neighbor upsampling
Stacked Hourglass Networks就是将多个Hourglass Network(漏斗网络)stack起来,总体网络结构如下: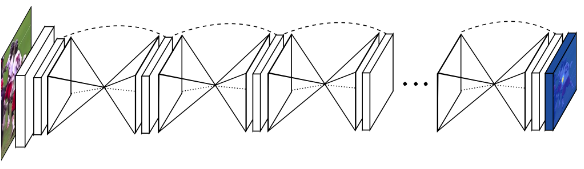
在每两个Hourglass之间,都有两层1x1卷积层,各个Hourglass之间还通过shortcut结构连接。
为了让梯度更好的传播,模型使用了Intermediate Supervision。每个Hourglass后的第一个1x1卷积层后面,会另接一个1x1卷积层输出一个heatmap,算一次损失。输出的heatmap会再接一个1x1卷积,与原来的第二层卷积结果相加后,送入下一个Hourglass。还有一些细节可以在下面的图中看出。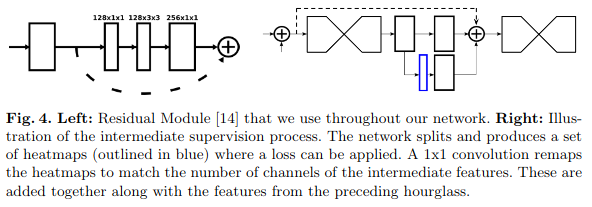
最终模型使用了8个Hourglass,在测试时只使用最后一个输出的结果。
Multi person: Top-Down
G-RMI(heatmap+offset), MASK RCNN, RMPE(STN+SPPE+SDTN)
CPN (Cascaded Pyramid Network)
这是一个Top-Down的多人姿态估计模型
主要解决的问题:人体各个关键点检测难度不同,较困难的点很难准确检测。因此,此模型的思路是,先检测比较简单的关键点、然后再检测较难的关键点。
上面已经提到了,Top-Down结构先检测人,再把每个人crop出来检测关键点。
首先简单说一下人的检测,论文里采用FPN + RoIAlign + Soft-NMS,FPN可以融合多尺度信息,RoIAlign是在Mask-RCNN中用到的代替RoIPooling的方法,Soft-NMS是对普通NMS(Hard-NMS)的改进,可以提高检测的召回率。
数据增强中,将检测出的图片先padding到固定长宽比后,再resize到固定大小。此外值得一提的是,在人体姿态估计任务中,Random Rotation用的比较多,一般会旋转某个随机度数,角度一般限制在(-30/45度, +30/45度)区间内。
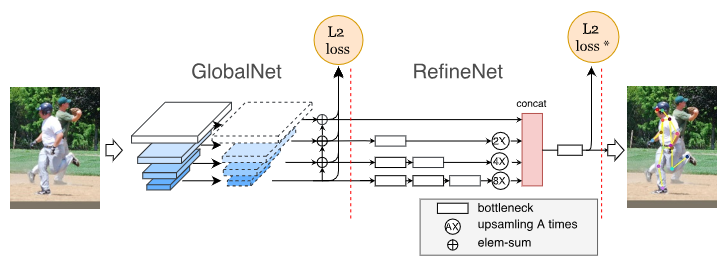
网络分为两个部分,GlobalNet 和 RefineNet。GlobalNet基于特征金字塔网络得到特征,RefineNet显式的处理“困难”点。
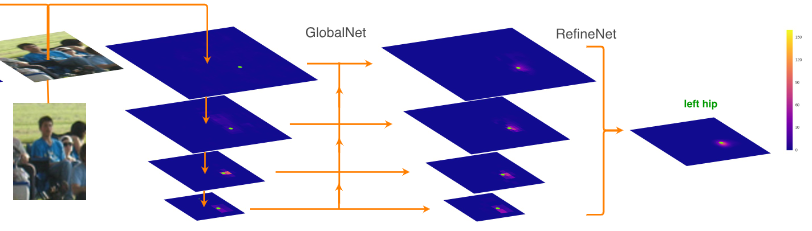
GlobalNet类似于ResNet+FPN,模型结构如图。ResNet部分将4个feature map取出后,经过一层1x1卷积即得到heatmap,送入类似于FPN的部分。与FPN不同的是,在融合多尺度信息的上采样过程中增加了一层1x1卷积。
RefineNet接收GlobalNet输出的4个feature map,使用常见的Hard Negative Mining策略,在训练时取损失较大的top-K个关键点计算损失,然后进行梯度更新,不考虑损失较小的关键点。
Multi Person: Bottom-Up
OpenPose(PAF)
OpenPose是一个Bottom-Up模型,此类模型在预测heatmap时使用单人姿态估计方法即可,主要问题在于如何找到关键点之间的联系,将各个关键点聚类到各个人。
OpenPose的主要思想是使用PAF(部分亲和字段),将属于一个整体的点连接起来。
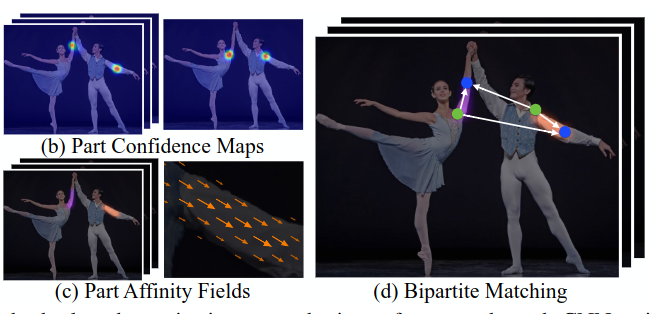
模型需要输出整张图片的heatmap即置信图S(如上图(b)部分),同时还需要预测出一个二维矢量场L(如上图(c)部分)。
- $S$ 即heatmap,与前面不同的是,这里的每个heatmap要提取出不止一个关键点,那就不能简单的取概率最大的点了,论文中使用了NMS来获得多个关键点。
- $L$ 对每个点用一个$\Delta x$和一个$\Delta y$表示其方向向量。
对于$L$,假设我们要对下图的胳膊提取关键点,两个关键点分别是 $x_{j_1,k}$ 和 $x_{j_2,k}$,其中的k代表第k个人。$x_{j_1,k}$到$x_{j_2,k}$这条线段两侧一定距离内(这个参数论文没讲怎么设)的点的groud truth,均为$x_{j_1,k}$到$x_{j_2,k}$的单位向量,其他点值为0。(若多个人的ground truth有重合,则取平均值)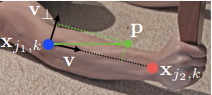
在预测时,$x_{j_1,k}$到$x_{j_2,k}$线段上均匀取m个点,他们每个点预测的L(双线性差值得到),与$x_{j_1,k}$到$x_{j_2,k}$单位向量的乘积之和,即为$x_{j_1,k}$和$x_{j_2,k}$之间的连接权重。
下图为模型的主要结构,其中F为图片经过VGG的前10层得到的feature map。模型同样采用multi-stage结构,在每个stage都算一次loss做中继监督。每个stage的输入为上一个stage输出的S、L及F的concat结果。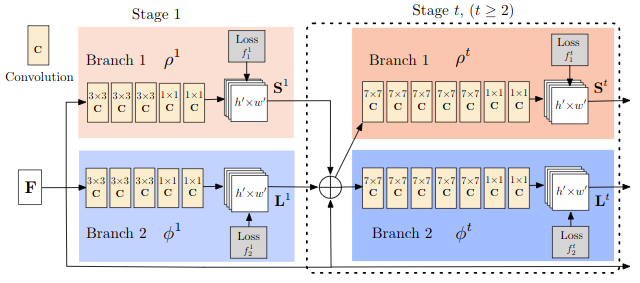
现在知道了各个点及他们之间的连接权重,使用二分图匹配的匈牙利算法即可找到最终配对。
评价标准
- 单人姿态估计PCK: Percentage of Correct Keypoints (PCK),关键点与groundtruth间的归一化距离小于设定阈值的比例。
- 多人姿态估计mAP: mean Average Precision (mAP),物体检测任务中使用IoU(Intersection over Union)来评价预测与真实标注之间的差异,在人体骨骼关键点检测任务中,我们使用OKS(Object Keypoint Similarity)代替IoU,对选手预测的人体骨骼关键点位置与真实标注之间的相似性进行打分。
总结
- 目前单人的姿态识别技术已经很成熟,速度也比较快,一般需要较大的感受野。
- 多人的姿态识别top-down的方法总体来说效果好于bottom-up的方法,而bottom-up的速度明显要优于top-down。如果要求实时的话可以选择OpenPose。